If you’re building AI agents today, you’re not choosing an LLM. You’re choosing the right LLM for a specific job. That is a much harder problem.
What is Algolia’s LLM leaderboard
Algolia's new LLM Leaderboard evaluates how large language models perform when they power real search and shopping agents. It tests them through Algolia's Agent Studio orchestration layer, where models do real work: interpreting queries, calling search APIs, and composing responses from live product data.
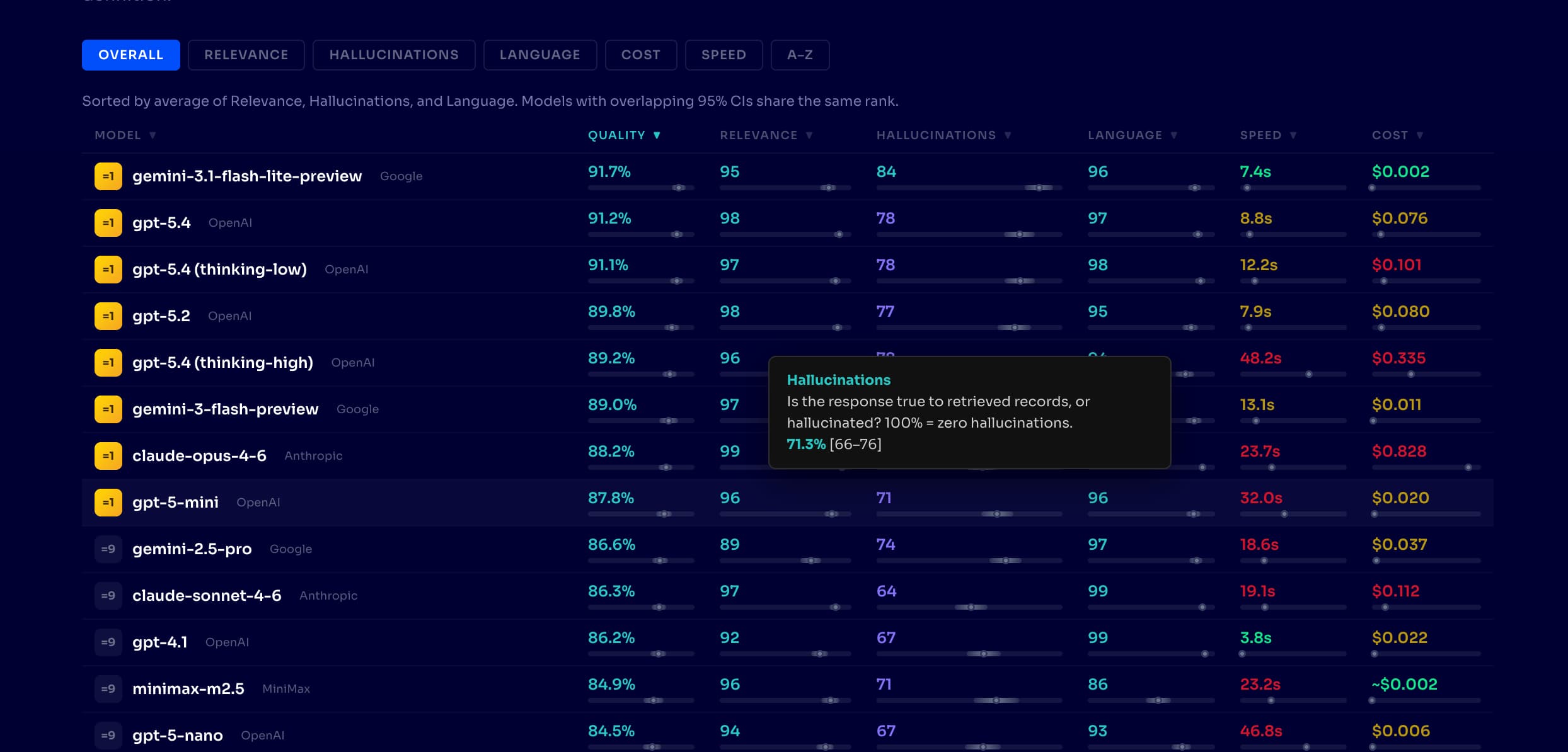 We test 24 models from OpenAI, Anthropic, Google, xAI, and open source alternatives like MiniMax and Qwen against real product catalogs, measuring three things that matter in production, whether:
We test 24 models from OpenAI, Anthropic, Google, xAI, and open source alternatives like MiniMax and Qwen against real product catalogs, measuring three things that matter in production, whether:
- The agent recommends relevant products (Relevance);
- It invents facts that aren't in the search results (Hallucinations); and,
- It adapts coherently to the customer's language, across 12 languages (Language).
Every score includes a statistical confidence interval. No point estimates, no "trust us" rankings. If two models overlap in confidence intervals, we say so.
Why Algolia built it
The model landscape shifts monthly. Choosing a model is an ongoing evaluation across quality, cost, latency, and task fit.
Generic benchmarks like MMLU or HumanEval measure raw LLM capability. They do not tell you how a model performs when it is orchestrating search queries, interpreting product catalogs, and composing responses through an agent framework. Developers need evaluation data from the actual deployment context.
The goal is practical. Help developers narrow a field of 24+ models to the two or three that fit their use case, then validate those candidates against their own data. A leaderboard is a pre-filter for experimentation, a starting point.
The problem with “best model”
There is an uncomfortable truth. The number one model on a leaderboard is often the wrong choice for your agent.
Our data makes this concrete. Rankings shift as models improve, but the pattern is consistent. At time of writing, Gemini 3.1 Flash Lite tops our leaderboard at 92% quality for $0.002 per query. GPT-5.4 scores 91% at 35x the cost. Claude Opus 4.6 scores 88% at $0.83 per query; 375x the cost of the leader for lower quality. Open source models like MiniMax M2.5 and Qwen 3.5 deliver 82-85% quality at sub-penny costs, proving you do not need a frontier model for every task.
Latency tells a similar story. GPT-5.4 with extended thinking scores 89% but takes 48 seconds to respond. The same model without extended thinking takes 9 seconds at 91% quality. More thinking made it slower and worse.
The real question is: which model is best for this exact workflow at this price point?
Where the Algolia LLM Leaderboard fits
Algolia’s LLM Leaderboard is designed to help developers choose models for real world use cases, instead of abstract benchmark rankings. It evaluates models in the context of how they are actually used in applications, particularly in search, retrieval, and agent workflows.
You can explore it here: https://algolia.com/llm-leaderboard/
What makes it different
Most leaderboards report a single score. We report the full decision surface.
Agent-level evaluation. We test the complete Agent Studio orchestration stack: query interpretation, search API calls, result processing, and response generation. A model that aces benchmarks but mishandles tool calls will show it here.
Confidence intervals on every score. Each model is evaluated across 500+ test cases and multiple independent runs. Every quality score carries a 95% confidence interval. When Gemini 3.1 Flash Lite scores 92% [90, 94] and GPT-5.4 scores 91% [89, 93], the overlapping intervals tell you the difference is noise, not signal.
Difficulty-tiered test cases. Our test cases are generated from real product catalogs at graduated difficulty levels. An easy case might be "compression socks," a direct product match. A hardcore case looks like this, from an actual eval: "I need a musical instrument gift for my nephew's birthday. Actually wait, I'm getting confused—my daughter just asked for a guitar kit for beginners (she's 8, likes pink), but the nephew wants something different..." The agent has to handle contradictory intent, age constraints, and preference shifts. This is where orchestration quality shows.
Latency beyond "fast or slow." We measure both time to full response and time to first token, because in a streaming agent UX, what users perceive as speed is how quickly the response starts. These are often very different numbers, and the distinction matters for product design.
Cost per query from actual token usage. Measured prompt and completion tokens multiplied by published rates. When a provider does not report tokens (some do not), we estimate response length and flag it as an estimate.
Why this matters for agent builders
When you are building multi-step, tool-using, or retrieval-augmented systems, your model choice affects everything.
Reliability becomes critical because agents fail in subtle ways. A model that performs well in benchmarks might still hallucinate product features, mishandle structured outputs, or lose context mid-chain. Our Hallucinations metric measures whether agents invent claims beyond what the search results contain. Models evolve constantly, but the spread we observe today is dramatic: top models ground over 80% of claims while others in the same price tier drop below 50%. Same agent framework, same product catalog, wildly different factual reliability.
Cost compounds fast. Agents amplify cost through multi-step reasoning, tool calls, and retries. Across our 24 models, cost per query ranges from under $0.01 to over $0.80; roughly a 100x spread even among current-generation models. Having visibility into both pricing and quality helps teams find the efficiency frontier, the set of models where no cheaper alternative scores higher.
Latency shapes the product experience. Your agent is part of a user interaction, and response times from 5 seconds (Gemini 2.5 Flash) to 48 seconds (GPT-5.4 thinking-high) create fundamentally different experiences. Faster models often outperform more capable ones simply because they create a smoother interaction.
Modern agents are increasingly modular. Different models may handle reasoning, summarization, and tool execution. A leaderboard that breaks down performance by metric makes it easier to design these orchestration strategies: use a high-Relevance model for query interpretation, a cheaper model for language formatting.
Use leaderboards, but do not rely on them blindly
Leaderboards are powerful, but they are a starting point. Our evaluation runs against e-commerce product catalogs, and your agent might handle support tickets, code generation, or medical triage. The ranking order may differ for your domain.
What transfers is the methodology. Confidence intervals, difficulty-tiered test cases, and latency breakdowns are evaluation patterns you can apply to your own data. What we report is a well-measured starting point. Reach out if you want to evaluate your own agentic search use case together.
Final thought
LLM leaderboards are quickly becoming a core decision layer in the AI stack. They show you what to build with, how to build it, and how much it will cost.
If you are building agents, they are no longer optional. They are part of your infrastructure.
Check out the new LLM leaderboard, or watch the presentation below from last week's Algolia DevBit where we first introduced it in a presentation called "Never trust your AI agent".
















%20(2).svg)

