As the old axiom goes: garbage in, garbage out. We need clean and optimized data so our product search and discovery tools work smoothly, otherwise our customers will never find what they’re looking for and we’ll never see their revenue. AI especially depends on good data — we can’t expect results if our input is subpar.
This becomes all the more challenging as our business infrastructure grows in complexity. If you’re working with omnichannel commerce, chances are that you don’t have the luxury of being handed structured, clean data on a silver platter. Since a great deal of our customers find themselves in this situation, we’ve put together a tool to make it easier to handle: Algolia Fetch! Fetch can help you retrieve, enrich, and transform data from all over the place as it goes into your index. Let’s look at some potential use cases:
Standardizing input
Imagine for a second that you have a million different vendors all selling on your marketplace, and all their product records are structured differently. Begging them all to standardize their catalogs would be a nightmare logistically, especially when inevitably you need to modify that record structure. The added friction would disincentivize new vendors from signing on, limiting how much our platform can grow.
How can we solve this problem? Well presumably, the only part of the data that really needs to be consistent before our revisions is a unique ID, just so we can tell the records apart and know when to either create or update them. The rest of the structure can be whatever, since we can just use an LLM to pick out the data that matters and recreate the structure you want. There are a couple tools out there that do this well, like Rectangle’s Shapeshift. However, since we’re working within Algolia Fetch, which already contains built-in functions to access OpenAI’s LLMs, it shouldn’t be too hard to just build this ourselves.
For our demo, I asked Anthropic’s Claude LLM to generate for me 10 different JSON objects for the same imaginary product, all containing the same information, but structured in a completely different and incompatible way. Then I added unique objectIDs to the dataset at the root level of each record just so we can tell the records apart and hosted the array on GitHub. If you’re curious about the different structures of product records it created, here’s how Claude explained its output:
These 10 different JSON structures all represent the same "Smart Home Hub" product but use completely different organizational approaches:
- Simple flat structure - straightforward key-value pairs
- Nested categorization - hierarchical organization by functional areas
- Array-based attributes - attribute-value pairs in a list
- Key-value pairs with metadata - adds metadata to each property
- Entity-relationship model - relational database-style with IDs
- Document-oriented with localization - supports internationalization
- Verbose XML-like nesting - deeply nested hierarchy
- GraphQL-inspired - node-based with fields
- Microservice-oriented - divided by service domains
- Event-sourced representation - temporal history of state changes
Each structure would require different parsing logic and adapters to work with the same application.
I’m not quite sure why some of those would ever be used in a production application, but I often find myself scratching my head when working with other people’s data, so it’s actually quite an accurate representation of reality. For the sake of simplicity, let’s say that its first idea (the straightforward key-value pairs) is the one that’s actually in our output format already, and we want the rest of the records to look like that. Here’s how it’s structured:
{
"objectID": "7b77ae55-da31-4134-a16c-4b0156ba83ef",
"name": "Smart Home Hub",
"description": "Control all your smart devices from one central hub",
"price": 149.99,
"currency": "USD",
"manufacturer": "TechConnect",
"category": "Smart Home",
"inStock": true,
"weight": 0.5,
"dimensions": "4x4x2",
"color": "White"
}
Some of the other records may not have this data, so we’ll make every field but objectID, name, and price nullable. inStock can default to true, and if the currency field isn’t for US Dollars, then we should convert it to US Dollars so we can drop the currency field altogether. Algolia has a built-in function for that that uses the Currency API, so we just need to get an API key.
Now that we have a dataset, we can add it into Algolia as a data source. Click on the Data Sources button at the bottom left of your Algolia dashboard (it looks like a silo), then the Connectors tab. Under the Home tab, you can click the Connect button for whichever connector best suits your data. I’m going to choose JSON.
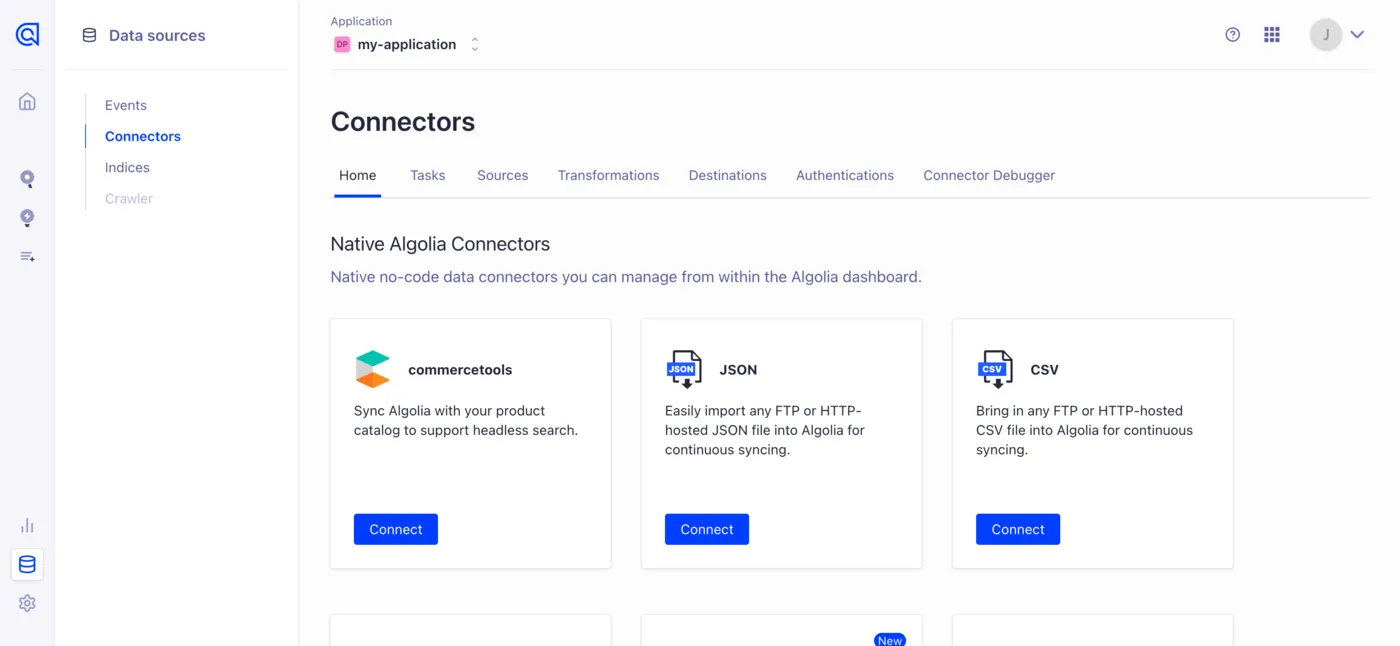
Then, it’ll ask a few questions about how to access the data, like where its located and whether Algolia has to authenticate to read it. Our “Unique property identifier” is that one consistent key we talked about earlier, just to tell records apart. I’ll put in objectID. Once the source is added, you’ll be able to reference it from any new connector. Since we’re building one now, it’ll take you back to the connector menu where you can click Create a transformation, which will show you a code editor like this:
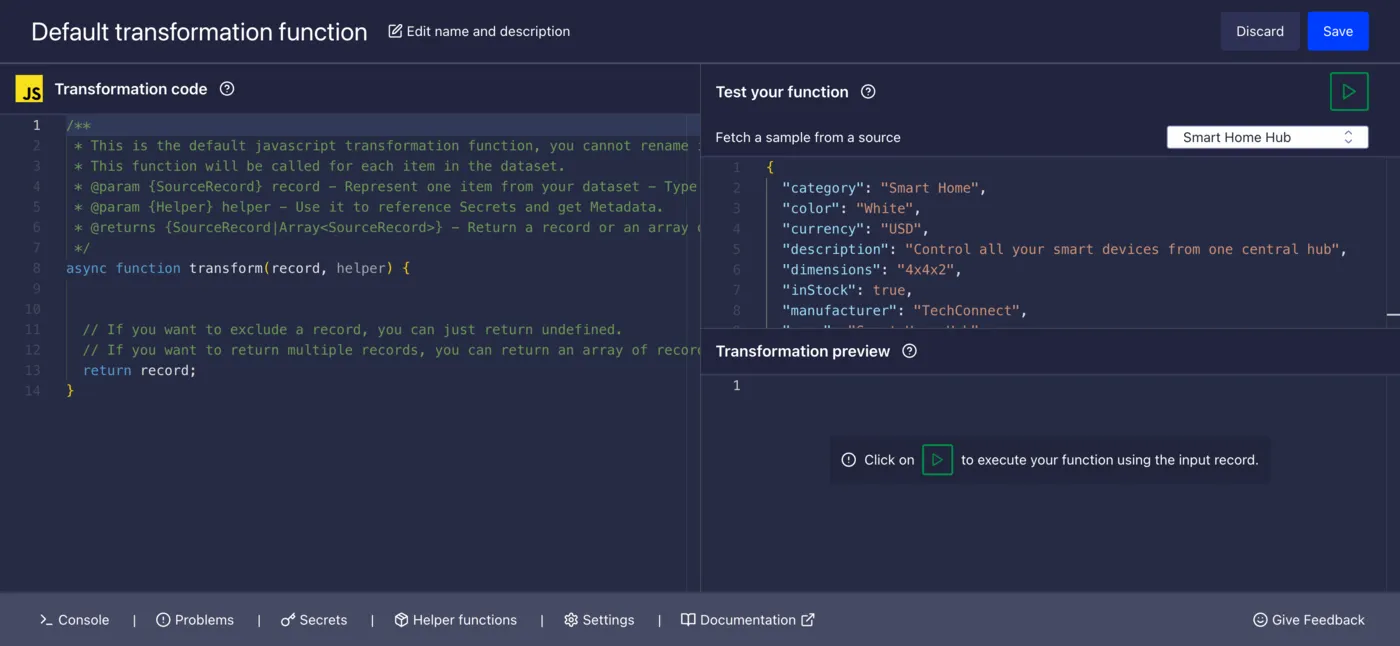
This is the cool part of Fetch, where we can do our transforming. That JavaScript function at the left is what will run the logic we’re building here. To help you, you have access not only to the record parameter, but also a helper, which gives you access to secrets and metadata. To learn more about that, you can click on the Secrets and Helper functions tabs below to get some templates added to your code, or just read the docs if you prefer. For our demo, you’ll need to add an OPENAI_API_KEY and a currencyApiKey to the secrets list, which you can do right in that Secrets tab.
In our code, we’ll just need to define the JSON schema we want our records to conform to, like this:
const json_schema = {
"name": "smart_home_hub",
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Name of the product."
},
"description": {
"type": ["string", "null"],
"description": "Description of the product. Can be up to three sentences."
},
"price": {
"type": "number",
"description": "Price of the product, in the original currency."
},
"currency": {
"type": "string",
"description": "Currency for the price, e.g. USD. Use three-letter abbreviations. If there is no data, default to USD."
},
"manufacturer": {
"type": ["string", "null"],
"description": "Manufacturer of the product."
},
"category": {
"type": ["string", "null"],
"description": "Category of the product."
},
"inStock": {
"type": "boolean",
"description": "Boolean representing whether the product is in stock. If there is no data, default to true."
},
"weight": {
"type": ["number", "null"],
"description": "Weight of the product in kilograms."
},
"dimensions": {
"type": ["string", "null"],
"description": "Dimensions of the product. Do not try to standardize this field."
},
"color": {
"type": ["string", "null"],
"description": "Color of the product, in all lowercase."
}
},
"required": [
"name",
"description",
"price",
"currency",
"manufacturer",
"category",
"inStock",
"weight",
"dimensions",
"color"
],
"additionalProperties": false
},
"strict": true
}
How this all works is documented on OpenAI’s website. The gist of it is that with this schema, we’re demanding that the LLM return output that is only in this format. Unless it refuses to fulfill the request completely for some reason (like if it deemed the output inappropriate), it will give us exactly the JSON we’re looking for given the right instructions. This feature is appropriately called Structured Outputs, and you can find it under other names in non-OpenAI LLMs too.
The next part is actually writing the function that calls the LLM. The default function is usually good enough for most use cases, but since we’re using Structured Outputs, we have to modify it a little. Now instead of being able to configure the maximum response length and the creativity temperature, we can configure the JSON schema the response must follow with the input parameter.
async function askGPT(config) {
const apiUrl = '<https://api.openai.com/v1/chat/completions>';
const messages = [{
role: 'user',
content: config.userPrompt
}];
if (config.systemPrompt) {
messages.push({
role: 'system',
content: config.systemPrompt
});
}
const response = await fetch(apiUrl, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + config.apiKey
},
body: JSON.stringify({
model: config.model,
messages,
response_format: {
type: "json_schema",
json_schema: config.json_schema
}
})
});
if (!response.ok) {
const errorData = await response.json();
console.error('LLM returned an error:', errorData.error?.message);
return null;
}
const completion = await response.json();
const completionMessage = completion.choices[0].message
if (completionMessage.refusal) {
console.error('LLM refused to fulfill this request.');
} else {
return JSON.parse(completionMessage.content);
}
}
Then, the function that puts it all together:
async function transform(record, helper) {
const newRecord = await askGPT({
apiKey: helper.secrets.get("OPENAI_API_KEY"),
userPrompt: JSON.stringify(record),
model: "gpt-4o-mini",
systemPrompt: 'You are standardizing a product catalog made up of product records from many sources. Pick out information from the inputted JSON and use it to create the output JSON according to the schema. Do not make up any answers from your knowledge - only use information from the input.Do not summarize any information.',
json_schema
});
if (newRecord.currency == "USD") {
delete newRecord.currency;
} else {
const currencyAPIResult = await fetch(`https://api.currencyapi.com/v3/latest?apikey=${helper.secrets.get('currencyApiKey')}¤cies=USD&base_currency=${newRecord.currency}`)
if (!currencyAPIResult.ok) {
console.error('Failed to fetch currency data - ' + (await currencyAPIResult.text()));
// in the event of a failed conversion, we'll just keep the currency value around for debugging and then null the price value so as to indicate an invalid price.
newRecord.price = null;
} else {
const jsonResult = await currencyAPIResult.json();
if (!jsonResult.data["USD"]) {
console.error(`Unable to find USD in the response`);
// in this error case, do the same thing as above
newRecord.price = null;
} else {
newRecord.price = Number((newRecord.price * jsonResult.data["USD"].value).toFixed(2)); // caps at two decimal places
delete newRecord.currency;
}
}
}
newRecord.objectID = record.objectID;
return newRecord;
}
It’s got our input record as the user prompt, some instructions in the form of a system prompt, and our JSON schema going into OpenAI. If the currency needs to be converted (which it doesn’t for my small sample of data, but I did test that it works if needed), then it does the conversion. Errors result in usable and debugable outcomes. It returns our new record with the original object ID intact, and the transformation is complete! I ran this on my subset of data, and aside from the different objectIDs, it transformed the 10 different structures Claude came up with earlier back into 10 identical, simple, searchable product records.
The last step is just to pipe this freshly-standardized data into a searchable index. You’re given the convenience of creating a new one or searching through existing ones on the same connector setup page.
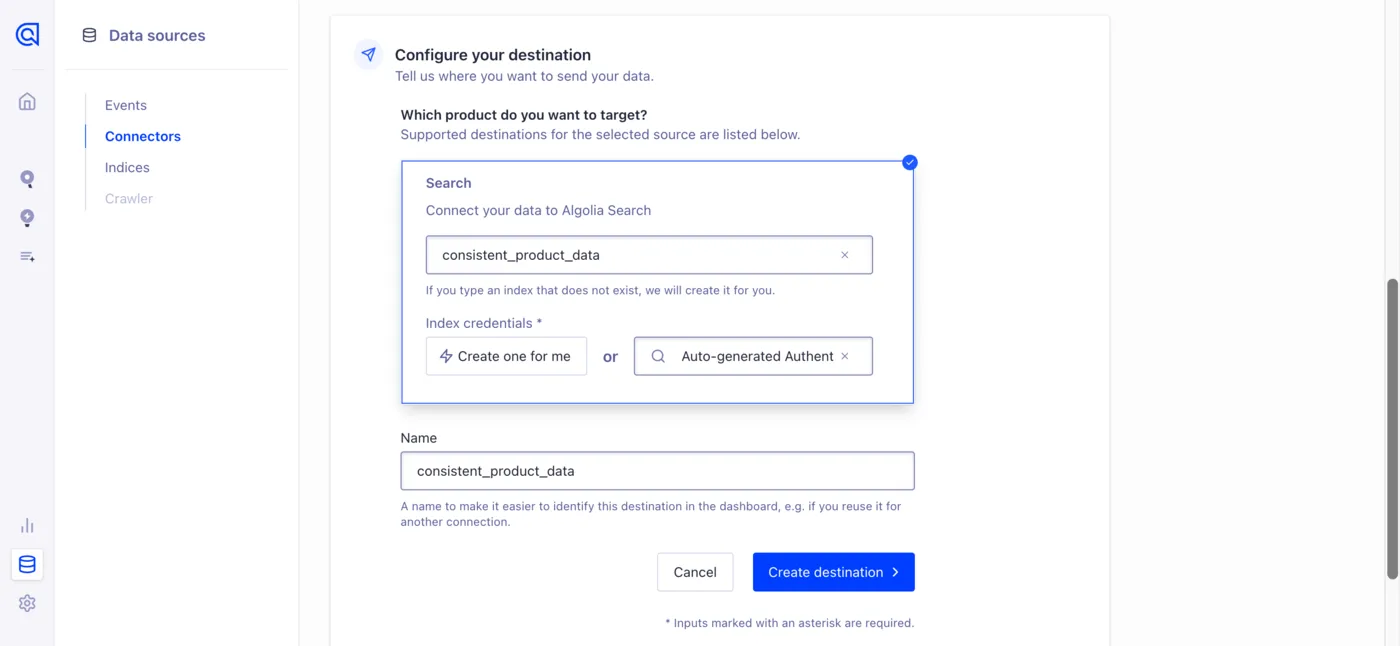
Then you get to choose whether your data is reindexed manually or on an automatic schedule, and in what manner. For help choosing, see this guide in the docs.
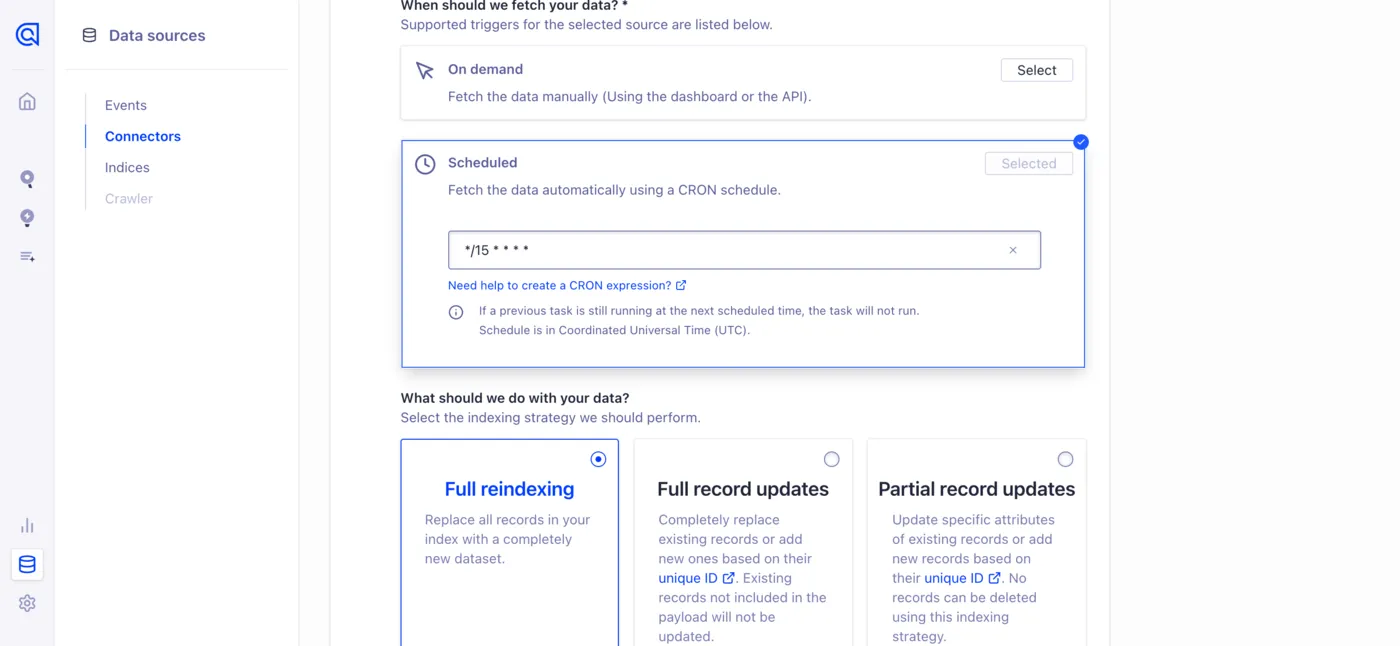
A full reindex every 15 minutes is a lot, but for an important production database on a big omnichannel ecommerce site, even a 15 minute delay for product updates may be too long. That’s a business decision that can affect revenue and customer satisfaction, so weigh your options carefully.
After you finish configuring the task, it should run itself according to your cron job. Once it runs, you’ll see the records continuously updated in the index you chose.
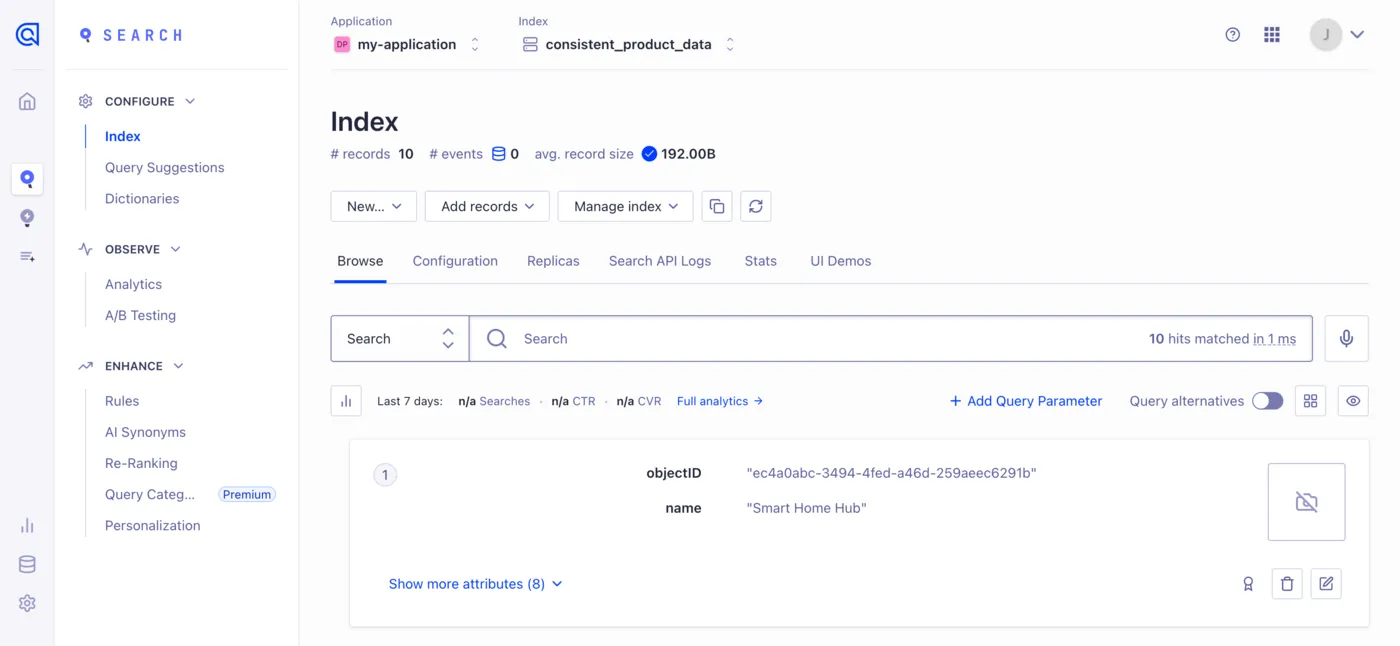
Now your omnichannel ecommerce platform is ready to search! All it took was a little AI magic and everything is standardized. The one downside to this is that the LLM usage bills can rack up. For this small demo, I only used less than $0.01 USD to test everything thoroughly, but a site with thousands of products updating every few minutes could bill quite a lot. So as an exercise to the reader, how might you go about adjusting the transformation function to use a self-hosted LLM? Here’s a hint: I’d start looking into Ollama and Deepseek's JSON Output feature. Conveniently, very little of the code would have to change.
Dynamic search data
Another problem we often run into is having our data for just one record spread across many sources. We did dip our toes in the water already with the currency conversions in the last example, but this could be taken a lot further. For example, many more industries are experimenting with dynamic pricing, and this pricing data likely isn’t stored right alongside the rest of the product information in the product database. In fact, how much of a product you have in stock probably isn’t stored there either if your stock is fluctuating so much that you need dynamic pricing. So that gives us three data sources that we need to combine to hydrate our search index:
- Our inventory management system returns objectIDs of what products we have in stock in the warehouse.
- Then, our product CMS can hydrate those records with static product information, like descriptions and images.
- Lastly, our dynamic pricing AI will add pricing information to our records.
This system is not too complicated if we have API access to all these different tools. The first step would be to add our initial data source — the inventory management system — as a connector, so that its record list gets passed through Algolia Fetch. If you’re following along with this article as a guide, just jump back to the previous section for more detailed instructions with images.
Let’s assume that our inventory management system returns a huge JSON array with perhaps thousands of entries, each of which is just an objectID and an object mapping warehouse IDs to the number of that product stored at that warehouse. Something like this:
[
{
"objectID": "b850c50f-ef18-4978-b7d2-30c9336924f8",
"warehouses": {
"montreal": 14,
"chicago": 45,
"phoenix": 32
}
}
]
I’m going to randomly generate a UUID for each objectID, and random numbers for imaginary warehouses in Montreal, Chicago, and Phoenix. Here’s the thing — it really doesn’t matter in the context of search exactly how many items are available in each warehouse, only whether the item is in stock somewhere. So if we want, say, three stock states available for display to our users (in stock, out of stock, and low on stock), then our transform function logic should start like this:
const totalStock = Object.values(record.warehouses).reduce((acc, cur) => acc + cur, 0);
if (totalStock == 0) {
record.stock = "out";
} else if (totalStock < 10) {
record.stock = "low";
} else {
record.stock = "in";
}
delete record.warehouses;
In English: sum up how much of this item we’re carrying in all of our warehouses, assign the item a designation of “out”, “low”, or “in” stock, then delete the unnecessary warehouse info.
To bring in information from any other source, we can just create a function in our transformation JavaScript code that takes our product’s unique identifier and returns everything that source knows about that product. Build this function for your product CMS API and for your dynamic pricing API, and you’ll end up with interchangeable, modular bits of data retrieval logic like this:
const getProductFromShopify = async (objectID) => {
// ... your lookup logic goes here
return {
objectID,
...productData
}
}
Then your transform function will just be putting these building blocks together, like this:
record = {
...record,
...getProductFromShopify(record.objectID),
price: getDynamicPricingData(record.objectID)
}
And of course, you can pass around whatever data you need. If your dynamic pricing data AI doesn’t know how much you have in stock, then you can wait to delete the warehouses key from earlier and pass that in. Whatever logic you need to run to accurately display these products to the users in the search results, you have a spot here. To finish up, just run through the same process as described above to add your source, write your transformation logic, and set up a task to update your index when you want.
Get started
Good search and discovery tools, perhaps even more so than many other parts of your business, depend on quality data. As much work as the expert engineers here at Algolia put into developing a resilient suite of tools just for this purpose, we can’t make up for bad data. Garbage in, garbage out.
Algolia Fetch streamlines the process of managing complex data and making it searchable. If you’re struggling with the intricacies of your business’ data, start prototyping with Algolia Fetch by clicking the Upgrade button in the top right of your Algolia dashboard and moving to a Premium or Elevate plan.






















%20(2).svg)

