The standout element of our algorithmically-driven modern Internet is the For You page. It’s ubiquitous wherever we consume video or audio content. But have you ever considered how it works? At its core, the seemingly magic For You page is actually the same technology we spend our days perfecting here at Algolia, just applied to video and audio instead of just to text. Building this involves surmounting a few challenges:
- First, we need to find a way to get some usable, searchable data out of our video/audio content. The actual data stored in the .mp3 or .mp4 file (or whatever other format we store it in) doesn’t actually encode the meaning that our users are likely to be interested in, unless they’re searching for videos with a particular frame rate or that contain a lot of blue. We need to somehow pull out the meaningful information for our AI search to digest.
- Speaking of AI search, we need an AI search engine. If you’re on this blog, you can probably guess that this is where Algolia will come in. More on that later.
- Also, we’ll need a way to query the search database. If we’re querying by text, that’ll be easy — just send the query straight to Algolia’s API and call it a day. The problem is, the assumption that the meaningful data we produced in step 1 will match the user’s queries might not be true. In fact, we might only get similar text queries if we use the same method we used in step 1 to parse every query on demand too, which would let us search using other pieces of audio/video content as long as the method can work on-demand through an API.
- Lastly, we need to keep track of whatever data step 1 gave us specifically about the songs or videos that each particular user plays. Sorting through that data should give us good queries to find similar content in the database.
For the sake of this article, we’ll implement these steps to build an audio-based For You page like something you’d find on Spotify or Pandora. In fact, the process we’ve described is essentially how Pandora came into existence. Step 1 was them building the Music Genome Project, “a unique knowledge base identifying hundreds of musical details for each song” in their dataset. That maps songs to moods, descriptions, lyrical themes — whatever might be relevant. They use a stock vector database (since their priority is recommendations, not search), and they just match the tags between the songs you like and the other songs in their database. What we’ll be building today is a small-scale version of that.
Tagging our music dataset
First step is to pick a training dataset. The MTG-Jamendo dataset is one of the industry standards, but there are plenty of others. Generally, what we’re looking for is a dataset of records that each represent a single song, with tags in the record that describe the music somewhat consistently. Soundcloud and Last.fm have databases like this too, so if you’re willing to mess with their APIs like I did, just click on those links for the docs. MusicBrainz is also an open-source database that contains this information, available through a slightly confusing API.
One good reason to go with a dataset that comes with instructions on how to set up your own music-tagging AI is that you can label songs that your sources haven’t ever heard before. If you’re trying to build a tool whose value proposition includes keeping up with the latest releases by the hottest artists, you can’t exactly wait for the Soundcloud labelling crew to settle on whether the song fits better as “joyful” or “jovial”. You need consistent labelling right away, and a custom AI can handle that easily. The MTG-Jamendo dataset, for example, comes with several Python scripts that train such an AI with PyTorch. If you’re up for a challenge, consider that your homework 😉
If we just use an off-the-shelf solution, then we can just skip steps 1 and 3, since we’re storing consistent descriptions in our search database and can query easily using those tags. In my case, I just uploaded my JSON array of song records to a new Algolia application and used the sample code the dashboard provided to spin up a simple search UI. This lets me search by tag, which is at least half the functionality we wanted.

As long as the searchable attributes are set correctly, everything should be working as expected. That’s steps 1 through 3 completed!
Recommending based on user data
The last step is where we bring it all together. If you’re planning on following along, I’ll put everything we write in this GitHub repo.
Assuming we’ve been keeping track of our users, we should have a list in our records of what each user has been listening to. Let’s build an algorithm to choose the next song for the user to listen to based on this history:
[
{
"objectID": "2a44b02c-0703-4c9c-a816-28778c7b4cf6",
"artist": "Simon & Garfunkel",
"title": "Bridge Over Troubled Water",
"tags": [
"uplifting",
"emotional",
"calm"
]
},
{
"objectID": "55de71dc-e173-4a56-a1b6-d0a37f2a27b4",
"artist": "Missy Elliott",
"title": "Get Ur Freak On",
"tags": [
"futuristic",
"funky",
"danceable"
]
},
{
"objectID": "779a63f5-9c3e-46d7-81ed-1a9fbc52c238",
"artist": "R.E.M.",
"title": "Losing My Religion",
"tags": [
"moody",
"emotional",
"introspective"
]
},
{
"objectID": "1472ebf5-7e2c-4f1b-9d6e-3f3e929fb6f7",
"artist": "Pixies",
"title": "Where Is My Mind?",
"tags": [
"moody",
"dreamy",
"grungy"
]
},
{
"objectID": "ca3a0d87-2485-48c5-b646-35f5298c63d4",
"artist": "The Velvet Underground",
"title": "I'm Waiting for the Man",
"tags": [
"gritty",
"cool",
"urban"
]
},
{
"objectID": "6c2b0f35-e32a-4b0b-9f4f-3d7fef0f5a5f",
"artist": "Radiohead",
"title": "Paranoid Android",
"tags": [
"moody",
"complex",
"epic"
]
},
{
"objectID": "9483e69f-331b-49f4-9584-0b66126a1b79",
"artist": "The Rolling Stones",
"title": "Gimme Shelter",
"tags": [
"dark",
"intense",
"emotional"
]
},
{
"objectID": "1c5f2c00-6a88-4c2d-aac5-318e3bc5e384",
"artist": "The Temptations",
"title": "My Girl",
"tags": [
"romantic",
"sweet",
"classic"
]
},
{
"objectID": "a8b50379-761f-4ea2-8434-f4b9335eb897",
"artist": "Beyoncé",
"title": "Crazy in Love",
"tags": [
"catchy",
"danceable",
"energetic"
]
},
{
"objectID": "ff2e1530-2567-4a61-9147-cc4c98f9bc1f",
"artist": "Prince",
"title": "Purple Rain",
"tags": [
"emotional",
"epic",
"soulful"
]
}
]
In client-side JavaScript, we can find the 5 most commonly occurring tags in this set like this:
Object.entries(
userHistory
// 1. combine all the tags into one big array
.flatMap(record => record.tags)
// 2. map each unique tag to the number of times it appears
.reduce((result, value) => ({
...result,
[value]: (result[value] || 0) + 1
}), {})
)
// 3. sort the tags by the number of times they appear
.sort((x, y) => y[1] - x[1])
// 4. remove the appearance count numbers
.map(record => record[0])
// 5. pick the 5 most common tags
.slice(0, 5)
For this particular user, this produces:
['emotional', 'moody', 'danceable', 'epic', 'uplifting']
An interesting combo, for sure. Let’s figure out what else they’d like.
Since we’re not looking for precision, we can actually just smash these words together into a query like this: emotional moody danceable epic uplifting. As long as we run this query in the optionalWords config option, then Algolia will return any result that contains at least some of these words, prioritizing the results with multiple matches. We also need to weed out any records that we’ve already played earlier in the playlist, so we’ll dynamically filter out those objectIDs. Also, we only need one record at a time, so it would be pointless to request more than one hit. That search request ends up looking like this:
const response = await algoliaClient.searchSingleIndex({
indexName: 'for-you',
optionalWords: [
commonTags.join(" ")
],
searchParams: {
filters: playlist.map(song => `NOT objectID:"${song.objectID}"`).join(" AND "),
hitsPerPage: 1
}
});
Keeping track of the whole playlist and where we’re at in it lets us build a UI and hook up our code to buttons that the user can actually interact with. This is what mine looks like:
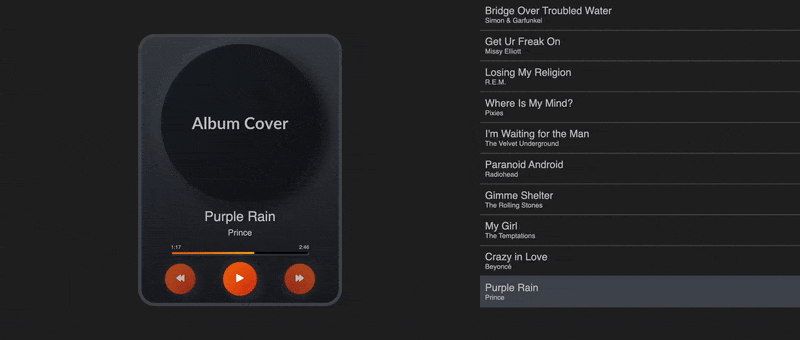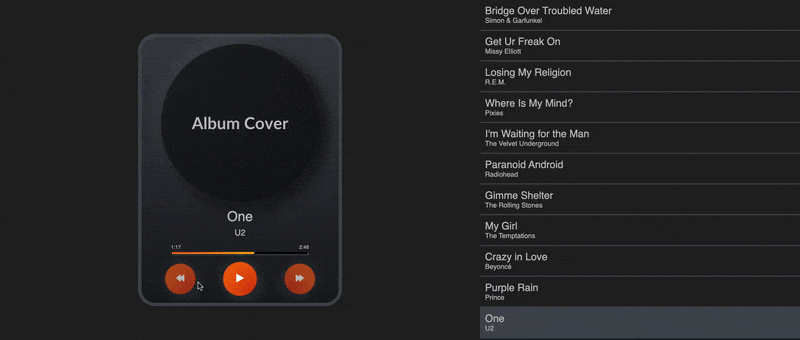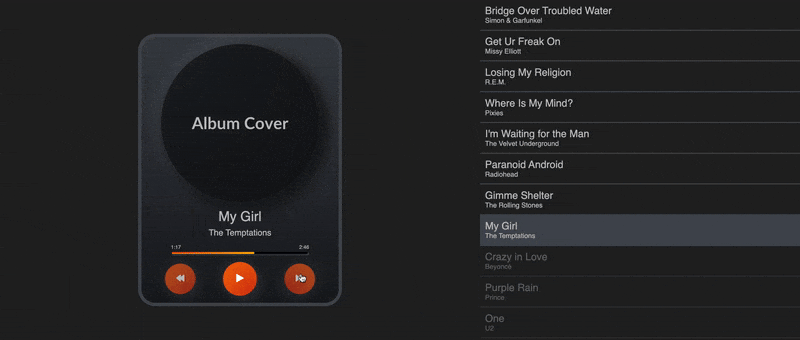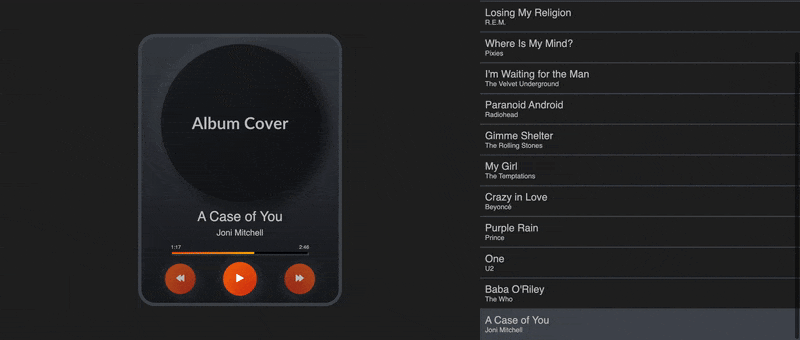
Of course, you can always find the code in the GitHub repo. In that GIF, Algolia is recommending those new songs whenever we bump into the end of the playlist based on the most similar songs in our database to the earlier playlist.
Don’t be limited by your data
With this type of system, we can make a searchable index out of any type of content. For example, we’ve helped several clients set up visual image search, and we even made a tutorial guide for it. It’s the same overall process as we described at the beginning of this article, except that there are even more third-party APIs available to tag your images consistently.
The possibilities don't end with music and images. You could apply this same approach to recommend movies based on plot themes, books based on writing style, or even recipes based on ingredients and cooking techniques. As long as you can tag your content reliably, Algolia is flexible enough to fuzzy match those tags.
For many companies, simple site search is all they need — Algolia can handle that in just a couple minutes. But to really impress users and maximize the revenue potential of your website, these sophisticated additions are the way to go. Figuring out what unique discovery challenges you can solve with search technology is the how you bring real value to your potential customers and keep them with your business. If you’d like to chat with our creative engineers about how Algolia can power something like this for your business, just ask for a demo! We would love to work together 🙂
 Starten Sie kostenlos
Die weltweit fortschrittlichste KI-Suche
Starten Sie kostenlos
Die weltweit fortschrittlichste KI-Suche AI Browse
Von KI erstellte Kategorie- und Sammlungsseiten
AI Browse
Von KI erstellte Kategorie- und Sammlungsseiten AI Recommendations
Vorschläge überall auf der User Journey
AI Recommendations
Vorschläge überall auf der User Journey Merchandising Studio
Datengestützte Kundenerlebnisse, ohne Code
Merchandising Studio
Datengestützte Kundenerlebnisse, ohne Code Merchandising Studio
Datengestützte Kundenerlebnisse, ohne Code
Merchandising Studio
Datengestützte Kundenerlebnisse, ohne Code Analytics
Alle Ihre Erkenntnisse in einem Dashboard
Analytics
Alle Ihre Erkenntnisse in einem Dashboard UI Components
Pre-built components for custom journeys
UI Components
Pre-built components for custom journeys






%20(2).svg)
