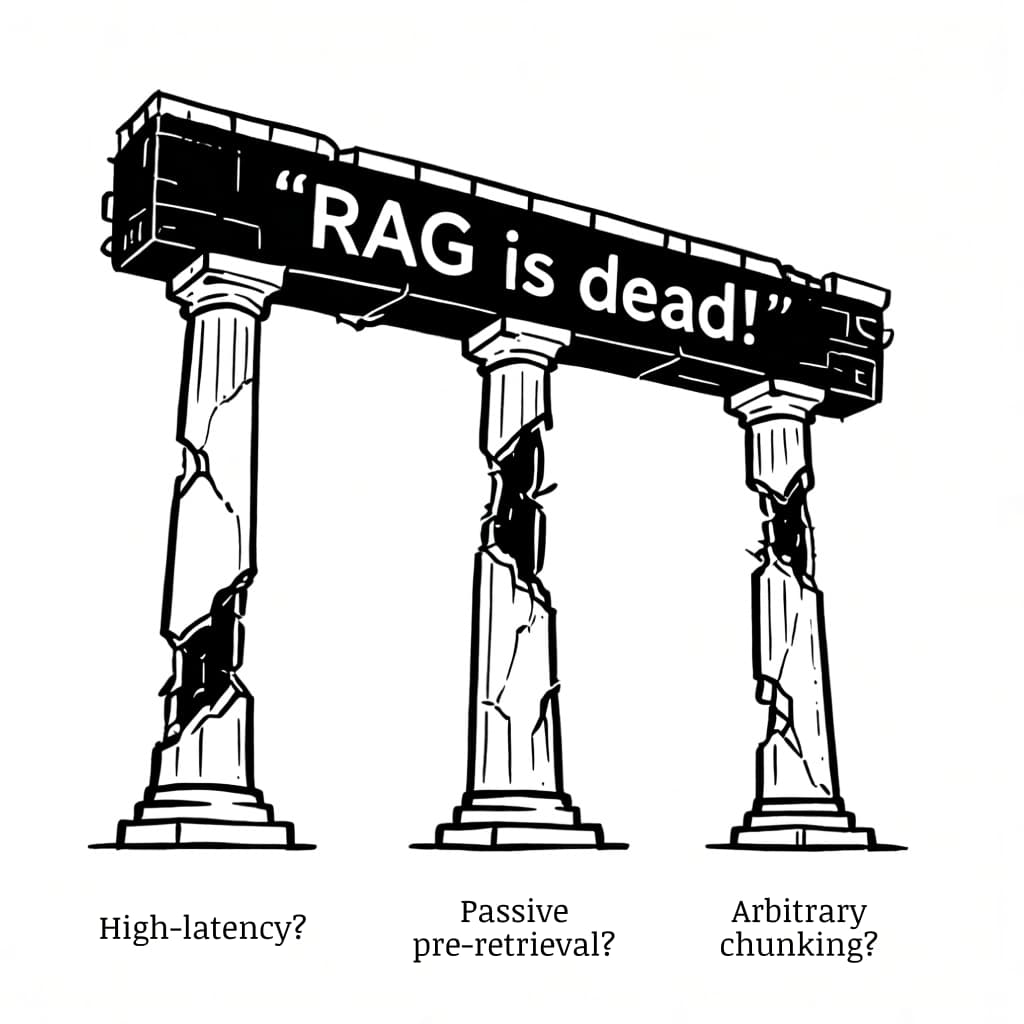
High Latency: They say that RAG pipelines are slow because embeddings, vector retrieval, and reranking introduce multiple stages, making production deployments costly and inefficient.
Passive Pre-Retrieval: They say that RAG retrieves all chunks before the model runs, leaving the model unable to dynamically query or refine its search based on intermediate reasoning.
Arbitrary Chunking: They say that dividing documents into chunks is brittle and difficult; poor chunking can split important context, degrade relevance, and complicate retrieval.
Instead, they argue that since modern agentic systems can search, inspect, and act dynamically over documents or code without any vector search involved, these must be the next evolution beyond RAG. These arguments seem convincing, but they’re actually arguments about bad RAG implementations, not about retrieval itself. Why can we say that?
The pillars holding up the claim that RAG is dead aren’t very strong.
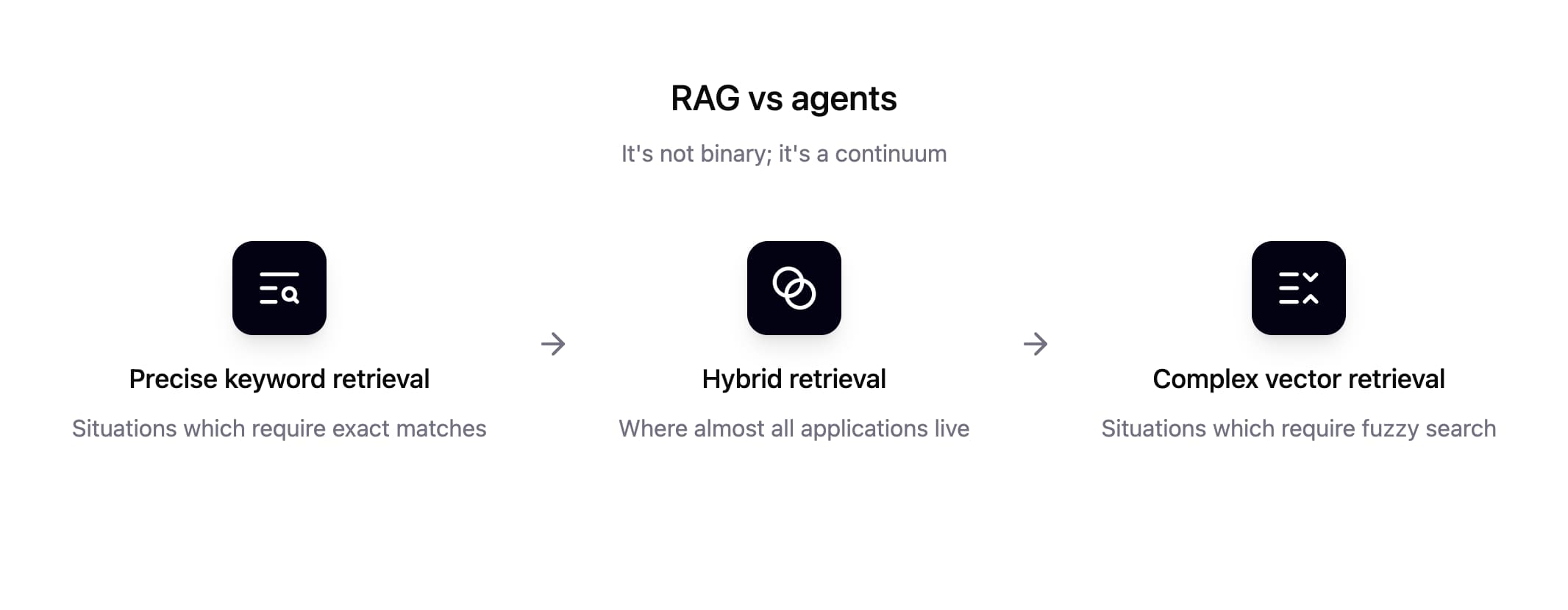
RAG to agents — it’s a continuum
Pop quiz! What does RAG stand for? You probably knew that one: Retrieval Augmented Generation. In other words, the AI model is asked to augment its generated output with the results of some retrieval operation, fetching structured data as needed to inform the results. So if an agent is searching through code or some other document store with tools like grep and glob, and using that retrieved data to augment the generated output… how is that fundamentally different from RAG?
grep is an excellent tool for precise, exact search. And in the case of code, it makes a ton of sense to use it because code is consistent. The agent doesn’t have to worry if someone is using non-standard keywords or syntax that doesn’t compile. The whole point of code is its consistency! That’s why grep is now standard tooling in almost all autonomous coding agents. But at its core, it’s just basic keyword search, and the moment you step outside its intended use case, the usability plummets. Try instead searching through a database of recipes for “easy weeknight meals”, and grep becomes useless because despite its remarkable precision, it just isn’t the right tool for the job. it has no semantic understanding of the content. And this applies to code too, since good code is well-documented in plain English. grep is perfect for finding consistent keywords, but you’ll need something fuzzier to fully grasp the intent of the author via their comments and docs.
In reality, retrieval isn’t binary. It’s not RAG vs agents; there’s a continuum between the simplest, most precise keyword matching and ultra-complex vector math. The type of retrieval you need should be picked for your application specifically, and it’s almost 100% of the time going to be somewhere in the middle.
When the model itself is in charge, deciding what it wants to retrieve and when, that’s an agent. But how much of each tool the agent uses for retrieval completely depends on which is best for the data it’s reading. And if your data is consistent enough that you can tweak the balance between keyword and vector beforehand and just let the agent query one blended retrieval engine, your agent never has to think about that balance. It just submits queries and gets back relevant results. This is the main point:
When hybrid keyword and vector retrieval is fast, structured, predictable, and directly callable by the model, the distinction of RAG vs agents becomes obsolete.
Algolia collapses the continuum
That’s our main selling point here at Algolia. We give you a hybrid keyword and vector retrieval engine called NeuralSearch that slots in perfectly instead of a more limited retrieval tool like grep. No need to build out all that complex indexing and ranking infrastructure yourself — we’ve spent the past decade on that problem. We’ve even wrapped it up nicely in a framework called Agent Studio that integrates with NeuralSearch automatically, giving you all the benefits of agents without the tradeoffs of ditching vectors.
Driven by the model
NeuralSearch can be called directly by the agent just like grep. It won’t be depending on decisions made by some external planner about what information it needs — the agent can decide for itself what to search, when to search, how to refine, and how many iterations to run. It’s the same process it would use with any other less-powerful retrieval tool: initial retrieval → inspect → refine query → filter → re-retrieval → resolve ambiguity. You get all of that agentic adaptivity without having to spin up any custom infrastructure because Algolia has neatly packaged it up in a simple API call the agent can access as a tool.
Nothing slows down generation
The cost of that iteration would be significant, but since Algolia was built from the ground up for speed and reliability, retrieval costs are actually negligible. Most of retrieval queries take from 1 to 20 milliseconds to process thanks to our distributed network of bare-metal servers around the world, all running a custom operating system designed just for this. Even indexing is lightning fast, since each new record is updated without affecting the rest of the dataset, as opposed to replacing the entire dataset on each indexing (which would be very slow). Most of the operations NeuralSearch runs are run in parallel, so it can pack in extra features like ranking rules, filters, facets, and way more without affecting latency.
Chunked at natural semantic boundaries
Instead of slicing content into arbitrary chunks, Algolia lets you index information at natural semantic boundaries like sections, headings, fields, and metadata. This means the model will retrieve coherent units instead of fragments, avoiding the broken context, duplicated meaning, and retrieval drift that poorly designed RAG pipelines famously suffer from. This matters because most real-world document stores — think knowledge bases, product catalogs, policy documents, manuals, etcetera — are structured domains where well-formed indexes consistently outperform raw file access patterns like code search, table parsing, or grep-style matching that don’t understand hierarchical document structure. The vast majority of enterprise text content is already built like this, so tools that deliberately ignore that structure are at a big disadvantage. The exceptions to that trend (like unlabeled financial reports) can be chunked at sentence or paragraph boundaries and searched through using a keyword-heavy NeuralSearch configuration, essentially replicating grep but with all the extra features (like filtering by content section and understanding synonyms). Algolia’s data model aligns with the way real-world information is authored and consumed, giving the LLM cleaner context and more reliable results.
A more accurate view of the landscape
It’s not that RAG is dead — it’s that the naive, slow, passive implementations of RAG are (and have always been) suboptimal. Great retrieval is still the #1 low-hanging fruit upgrade for agents, and it requires a retrieval engine that’s model-driven, fast, semantically structured, cheap to iterate, and predictable at scale.
That’s Algolia: the backbone of informed, modernized agents that get work done and drive real impact.











.avif)
%20(2).svg)
