There’s no single technology, model, or clever trick that will magically solve search. Great search systems are the result of combining many ideas, technologies, and strategies — and doing a lot of hard work to make them all play well together.
You might use models for query understanding and augmentation. You could classify queries and switch strategies based on the result. You might combine multiple retrieval systems — keyword, semantic, even image search. Then merge the results, apply ranking signals, personalize them, and finally pass the output through a large language model (LLM) to produce conversational responses.
That’s a lot of moving parts. Making them all work together requires planning, coordination, and what we call query orchestration — the process of blending different retrieval and ranking strategies into one coherent experience.
At Algolia, our search stack is exactly that: a complex orchestration of many different components, each bringing its own kind of value. There’s simply no single new technology that could replace it all.
This blog is based on a talk I gave at DevCon. Keep reading, or watch the recording of my presentation below. In the recording, I also give a quick tour of the tools we’re using to enable our building approach.
Prototyping in a complex system
When you’re building or improving a search system like this, your prototypes tend to fall into three categories:
Iterating on existing components — concentrating on improving one piece of the system.
Re-arranging or combining components in smarter ways.
Adding something new entirely — and deciding when and how to use it.
Take semantic search as an example. About five years ago, LLMs started to get good at encoding text into vectors, letting us match on meaning instead of just keyword overlap. Suddenly, you could handle conversational queries where users didn’t know the exact terms to search for.
It was a breakthrough — but not a replacement. Vector models still struggle with things like obscure brands, product SKUs, or part numbers. Even with fine-tuning, semantic search alone isn’t practical for every use case. The most effective systems combine both keyword and semantic search — another reminder that there really are no silver bullets.
The learning loop: Turning ideas into production
Prototyping in such a system is tricky. You need to figure out how a new idea fits with the existing pieces, which queries it should apply to, and whether the added complexity is worth the cost. More CPUs, more memory, more latency — it all adds up.
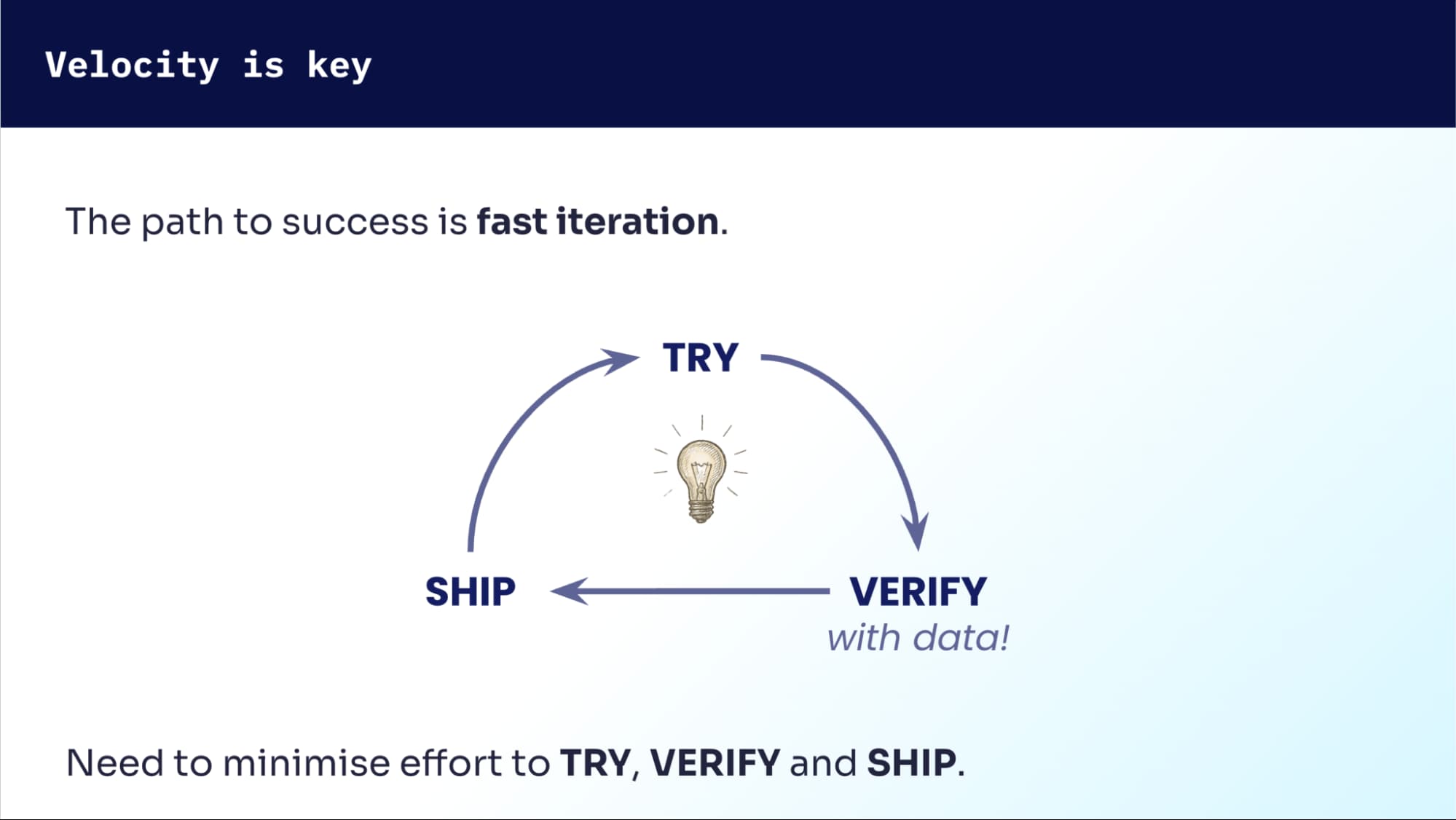
At Algolia, we tackle this with what we call a learning loop — a lightweight, repeatable process for turning ideas into production safely and quickly.
It starts with an idea — maybe you’ve seen a few poor search results and want to fix them.
You start by layering your idea on top of current production behavior and eyeballing the results.
Next, you validate it against historical or synthetic data to ensure you haven’t broken anything else.
Finally, once it looks solid, you ship it to production and observe it in the wild.
This loop lets us improve search continuously in small, measurable steps — compounding over time.
Building for velocity
To make this work at scale, we built an internal tool that makes it incredibly fast to prototype, test, and deploy new search algorithms.
Here’s how it works:
On one side, you can run simple keyword searches.
On the other, you can instantly modify the underlying algorithm — say, swapping in a vector search or merging two result sets.
You can even integrate an LLM to rewrite queries or generate more conversational responses.
Because the system is composable, every piece — keyword search, vector search, ranking, merging, LLM calls — is modular and can be wired together like building blocks. Instead of writing code, we define new algorithms as configurations. That means anyone, not just engineers, can experiment. We’ve had CSMs and product managers prototype changes that ended up in production.
Testing, verification, and safety nets
Once an algorithm is defined, our automated simulation system takes over. We replay historical queries (or synthetic ones generated by an LLM) through the new algorithm and measure performance using metrics like NDCG and recall. If something breaks, it shows up immediately.
This makes verification fast — often just a few minutes — and provides hard data to support decisions. If everything looks good, we can move to a live A/B test with real traffic in seconds.
Our iteration cycle is now incredibly fast:
Seconds to build and try an idea.
Minutes to verify.
Seconds again to ship a production test.
Compounding small improvements
This speed changes the equation. Because trying something new is cheap and safe, we can afford to experiment constantly. Each improvement might be small — just 1% better — but over time, these gains compound into major progress.
It’s also a great way to introduce new AI models responsibly. You can test them early, measure real-world effects, and ensure they don’t degrade core performance. The feedback loop gives you confidence to innovate safely.
And as we refine this system, we’re also laying the groundwork for the next frontier — AI-driven optimization. With composable components and a built-in feedback loop, we can start experimenting with agents that autonomously tune query algorithms.
One percent better every day
In a world where technology evolves fast, success depends on how quickly you can learn and adapt. The faster you can try new ideas, verify them, and ship them safely, the more likely you are to win.
That’s the essence of being 1% better every day. Invest in the process — build systems that make experimentation easy, verification fast, and deployment safe. Because when you do that, innovation becomes not just possible, but inevitable.












%20(2).svg)
