How do you deliver great ranking for the long tail of queries—when you don’t have enough user interaction data to learn from?
I’ll show you how we answered that question at Algolia. This post is a cleaned-up version of a talk I gave at DevCon 2025. It’s for developers who care about ranking quality, but also have to ship systems that scale, stay explainable, and don’t require constant hand-tuning.
If you prefer, you can watch the original presentation below.
The long tail cliff is real
Search systems are really good at learning from user behavior. Clicks, conversions, saves, plays—whatever “success” means in your product—those signals tell you what users actually want.
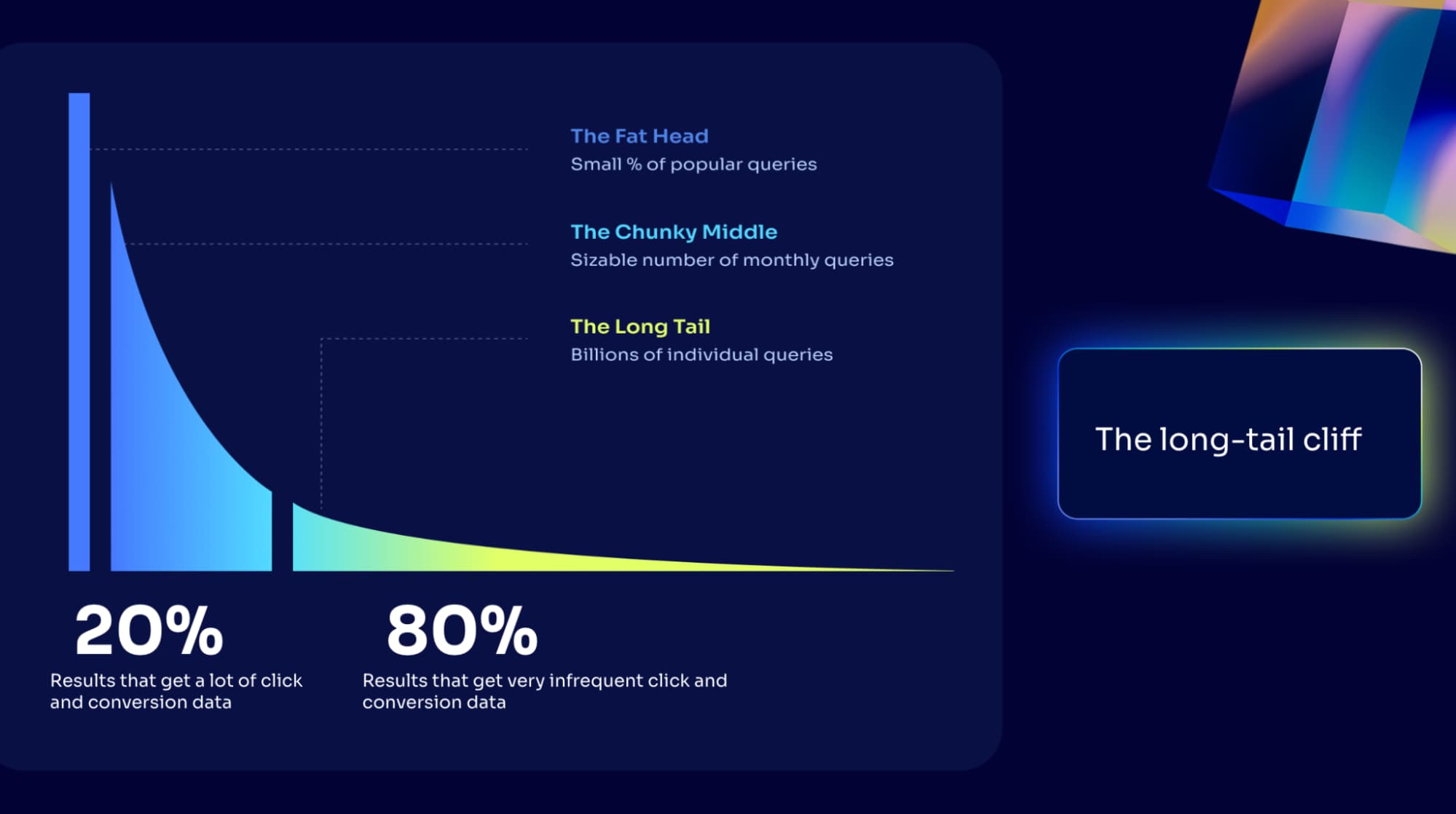
But most search applications follow a lopsided distribution:
A small slice of queries (often ~10–20%) have high volumes for engagement events.
The rest (the other ~80%) is a long tail: unique, specific, low-frequency searches.
For head queries, you get rich behavioral data and you can do a lot with it.
For long-tail queries, you often get… nothing. Or not enough to confidently learn anything. That’s the long tail cliff: a huge portion of your query space where event-based approaches can’t really operate.
And here’s the twist: those niche queries are often the ones with the highest intent. When someone searches for something very specific, they tend to know what they want—and if you rank well, they’re more likely to engage or convert.
So the question “how do we bring that same intelligence to queries we barely see?”
Start with what already works: Dynamic Re-Ranking
We didn’t start by inventing a brand new ranking system. We started with something that’s already proven in production: Dynamic Re-Ranking (DRR). DRR is the “wisdom of the crowd” applied to search results:
It watches what users do for a given query (clicks, purchases, plays, etc.).
It learns which results users consistently prefer.
It boosts those results for that query going forward.
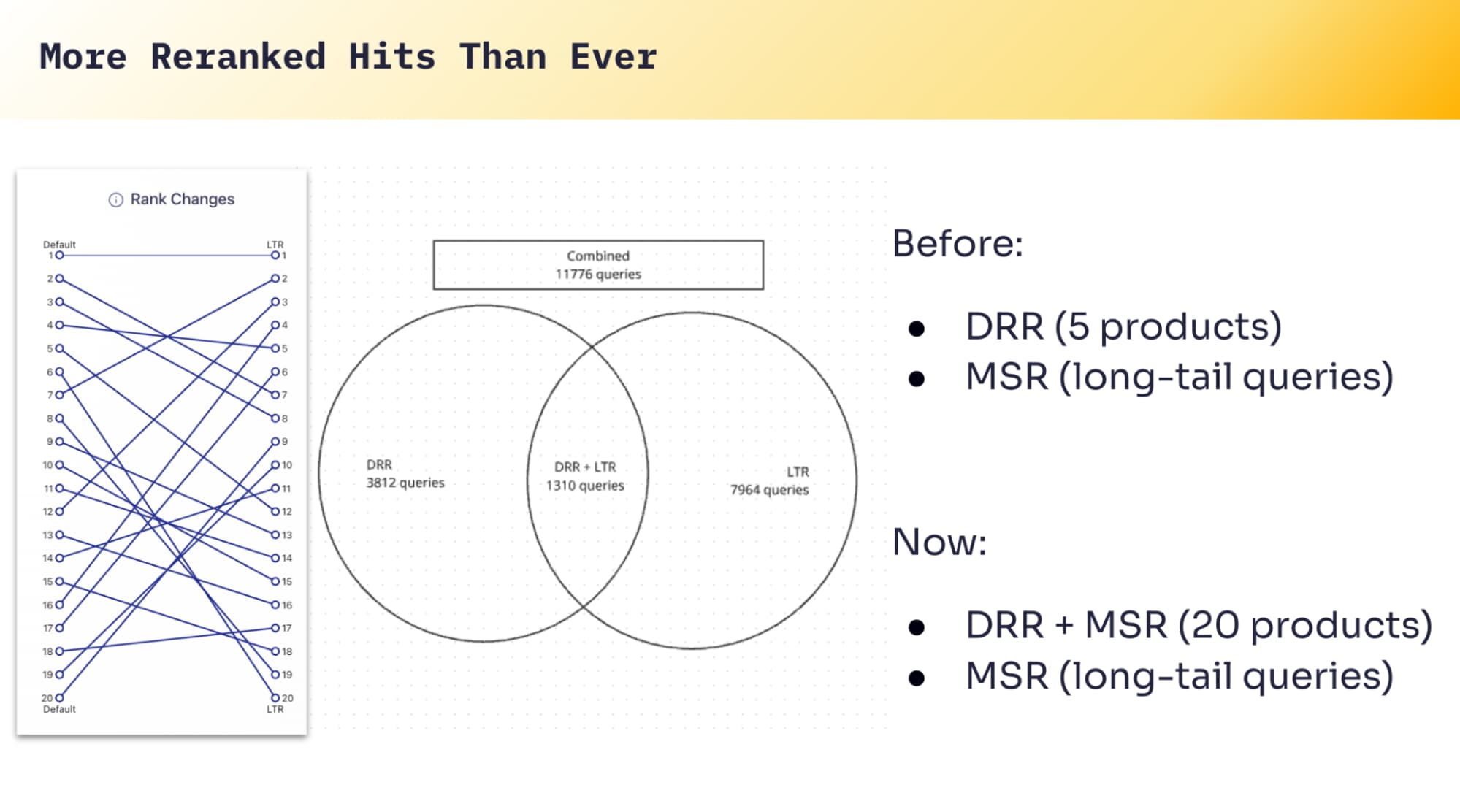
No rules to maintain. No manual tuning. DRR just learns from outcomes. And when you have enough data, it’s extremely effective. The limitation is also straightforward: DRR needs interaction volume for a query in order to learn. So it shines on the head, and fades out on the tail. Which leads to the obvious next step: Can we take what DRR learns on head queries and generalize it to long-tail queries?
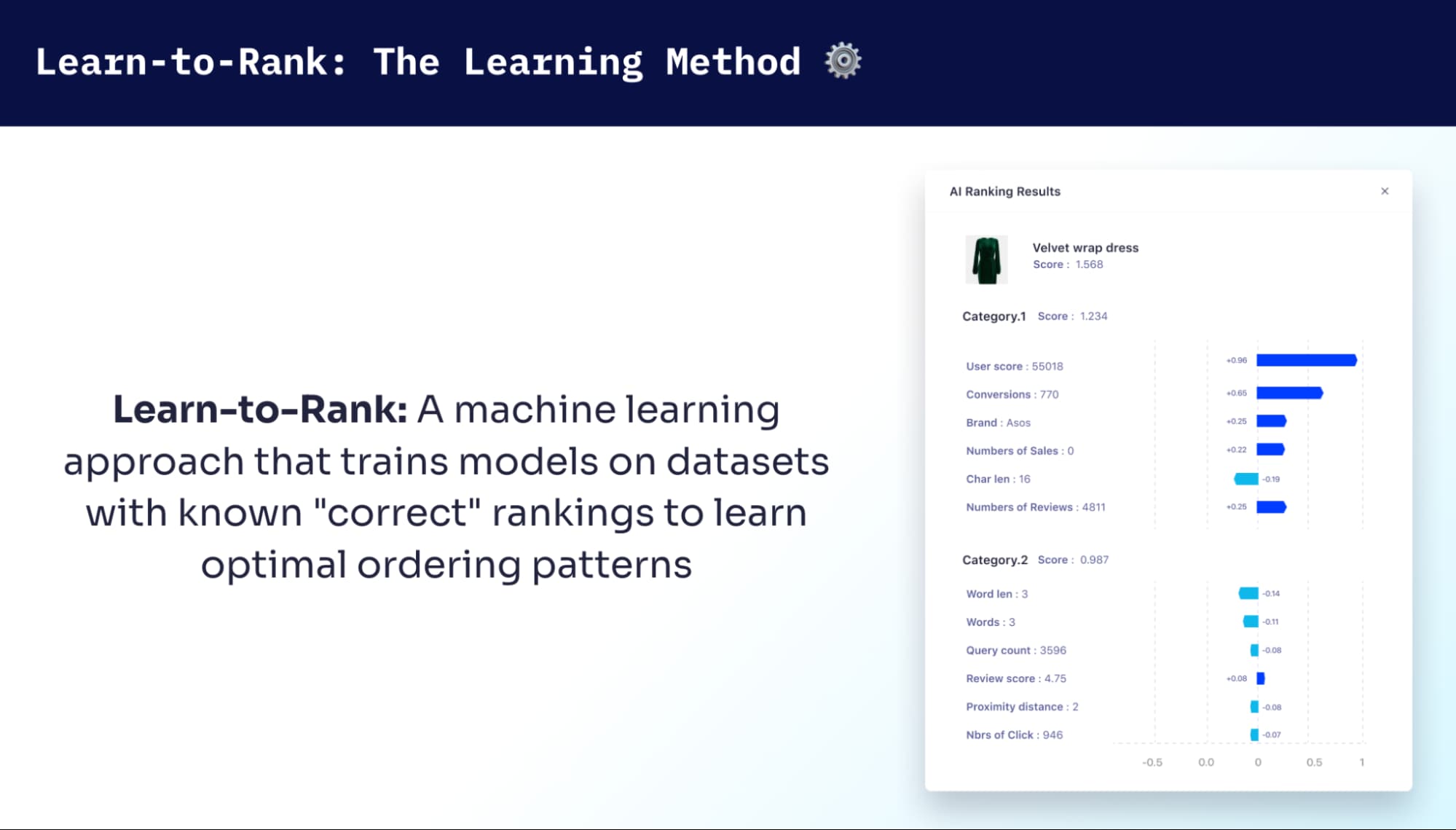
Learn-to-Rank is the bridge from “known” to “new”
Learn-to-Rank (LTR) treats ranking as supervised learning. You train on query–document examples where you already know what “good” looks like, and the model learns to produce a better ordering. LTR isn’t trying to predict a perfect relevance score. It’s trying to get the order right. It matters because ranking quality—especially the top of the list—is what users feel. If the first few results are strong, search feels successful, even if the tail of the ranked list isn’t perfectly calibrated.
There are a few common ways to do LTR:
Pointwise: predict a score per result and sort by it.
Pairwise: learn preferences between pairs (A should rank above B).
Listwise: treat the whole list as the unit you optimize.
We chose a listwise approach because it aligns with how ranking is evaluated and experienced. Metrics like NDCG care about ordering, and so do users. Listwise training optimizes the list directly instead of treating results as isolated predictions.
At that point, we had two ingredients:
DRR, which performs really well where we have behavioral data
LTR, which can generalize learned patterns to new, unseen queries
DRR already knows what ranking decisions lead to better outcomes on head queries.
MSR learns from those successful DRR decisions.
Then it uses a learning-to-rank model to apply that learning to long-tail queries, where DRR has little or no data.
i.e., MSR asks: “If Dynamic Re-Ranking knew about this query, what would it do?” It uses LTR to make that prediction.
Practically, MSR combines textual relevance with business signals—things like brand, price, ratings, inventory status, shipping speed—whatever your domain needs to optimize for conversions (or other outcomes over time). When it comes to MSR, scale matters. We’re not talking about “a few thousand popular queries.” The goal is to extend intelligent ranking across a much broader query space including tail queries that never accumulate enough behavioral data on their own.
When we apply these learnings, we can significantly expand coverage: instead of only ~20% of your query volume benefiting from learned re-ranking, you can bring intelligent ranking to something closer to ~80% of queries by generalizing from head to tail. And you can expand depth too—re-ranking more results per query when DRR alone would only confidently adjust a small slice.
Finding the right signals.
LTR models can ingest a lot of features, but irrelevant features can actively hurt you. What’s “relevant” is intensely domain-specific. Web search datasets might lean on signals like PageRank or CTR. Those are meaningless if you’re ranking products in a commerce catalog—or tracks in a music library—or courses in an education platform. At Algolia, being schemaless is important, but it makes this harder: we can’t assume which attributes matter for your application.
So we made a very deliberate product decision in MSR to give developers control over signal selection. You know what drives user decisions in your product. MSR is designed so you can test hypotheses like:
“Users prefer same-day shipping, but only if rating ≥ 4 stars.”
“Discount matters, but only for trusted brands.”
“Boost sellers, but only when review count is high.”
“Inventory status should prevent promoting items that can’t be purchased.”
You pick the attributes that reflect how your business works. Then the model learns how to weight and combine them based on what historically led to good outcomes. This is also how we enable teams to A/B test multiple data signals without requiring code changes. The point is to make iteration fast—because ranking improvements rarely come from guessing once and calling it done.
Iteration without guessing: SHAP values and interpretability
Once you deploy a learning-based ranking system, you immediately run into the “okay but why?” problem.
That’s where SHAP values (Shapley Additive Explanations) come in. SHAP is a method for explaining model predictions by estimating how much each signal contributed—either for a single result or averaged across many results. In reality, they don’t tell you “why” but they do provide important feedback on the strengths of each signal.
In human terms, SHAP helps answer questions like:
“Why did this item rank #3 for this query?”
“Which signals consistently boost results across the index?”
“Which signals don’t matter and should be removed or replaced?”
This interpretability is crucial. Ranking systems get complex fast, and if you can’t explain what’s happening, you can’t debug or improve with confidence.
For us, SHAP turns signal selection into a real engineering loop:
choose signals
train
inspect influence (SHAP)
refine
repeat
Where this goes next: goal-agnostic ranking
Right now, MSR learns from DRR, and DRR is typically optimizing for conversion-oriented outcomes. The underlying framework is goal-agnostic, meaning you could train the same system to optimize for different objectives such as:
engagement
revenue
discovery
business-specific goals (like balancing user satisfaction with inventory turnover)
From a technical standpoint, it’s “just” changing the training labels and optimization targets. From a product standpoint, it’s a shift: ranking stops being a one-size-fits-all setup and becomes something you can tune to what “success” actually means in your platform.
Closing
Multi-Signal Ranking is our approach to making sophisticated machine learning practical for real ranking problems:
Use behavioral data where it exists (DRR) as the best available signal of what users want
Generalize that learning to the long tail with listwise Learn-to-Rank
Keep developers in control through explicit signal selection and experimentation
Stay explainable with SHAP-based insight into why the model is ranking the way it is
If you take one idea from all of this, it’s this: Use the data you do have to teach the system how to behave where you don’t have data yet.
Try it yourself: sign up for a 100% free account. Our Build plan has access to many of our AI features, including AI-powered Dynamic Re-Ranking. Or get in touch so we can provide your team with a demo.
Gartner 2026 Magic Quadrant for Search and Product Discovery
A leader for the third consecutive year
Algolia is recognized as a Leader in the 2026 Gartner® Magic Quadrant™ for Search and Product Discovery as the market shifts toward AI-powered, agentic discovery.
Increased Operating Profit and Improved Efficiency
A Forrester Consulting study found Algolia delivered $3.1M NPV over three years, helping commerce teams improve relevance, automate merchandising, and grow revenue
IDC recognized Algolia as a leader in general-purpose knowledge discovery software, citing the growing role of search in AI-powered workflows and enterprise knowledge experiences
Algolia earned 12 medals across 12 categories in Paradigm B2B’s 2025 Enterprise Combine for Search and Discovery, with customers praising speed, transparency, analytics, and ease of use










%20(2).svg)









